
This page contains an introduction to the use of the library, notes on its design and some profiling results and thoughts regarding the design’s performance versus other methods. The source code can be obtained from GitHub (user: MikeBrownUK, repository: OutputStreams).
All code is licensed under the MIT with thanks to all I worked with who inspired its evolution in some way (see my blog for further details).
As background reading for those not terribly familiar with the history of character representation on computers and why it often makes developers want to cry, then a good place to start would be Joel Spolsky’s excellent article from almost twenty years ago.
Contents
Getting Started
Design
Performance Profiling
Getting Started
Here’s the expurgated guide to using the OutputStreams Library. For a better idea of the class relationships, I recommend you refer to the design description that follows this introduction and familiarise yourself with the source files.
Test Project
A CMake googletest project is included in the source package. To build the test program, you will need to download and install googletest and set GOOGLE_TEST_PATH to point to that directory (or you could edit all the paths in the CMakeLists.txt manually – your choice). CMakeSettings.json is also provided for Visual Studio users with Windows and Linux debug and release sample target configurations.
To use the source with an IDE and project/makefile of your choosing, add the OutputStreams, Utilities and appropriate googletest directories to your include paths and all .cpp files within OutputStreams and Utilities to your build list alongside the two mandatory googletest source files (gtest-all.cc and gtest_main.cc) and you should be good to go. I recommend you look at the CMakeLists.txt file regardless to note the compiler preprocessor defines. For Linux you will also need to link to pthreads.
Using OutputStreams
#include "StreamAndChannelAliases.h" using namespace mbp::streams;
OutputStream
Create an OutputStream. The easiest way is to use one of the predefined aliases I supply in the above file, specifying character width for the stream:
StreamStdOut< char > myStream;
This creates an OutputStream of char width that writes to std::cout. There are default construction parameters, so what you are actually specifying above is:
StreamStdOut< char > myStream( nullptr, OutputStamp::GetDefaultInstance(), &GetDefaultChannelSettings() );
The first parameter is not used by this stream type – it is just a pointer to a narrow string used to carry initialisation values to the OutputTarget the OutputStream flushes to (for a file stream this is the name of the file to create).
The second parameter is a reference to an OutputStamp class – these classes are used to add prefixes to entries sent to the stream. The default is an empty singleton that does nothing but satisfy the minimum required interface.
The final parameter is a pointer to a StreamSettings structure that contains initialisation values for message priority and filtering – details later.
You can use this stream as you would std::cout:
myStream << "some text followed by a number... " << 12 << endl;
Note the use of endl
std::endl would work in this instance, but I encourage you to use the version from my namespace as std::endl throws exceptions on Ubuntu Linux when put into streams of char16_t and char32_t type (at least with G++ version 9.4.0)
There is currently one other manipulator you should use rather than the Standard Library version: setw. This is to ensure all code compiles away with the Microsoft compiler when you substitute a NullStream for your stream/channel via aliasing. If I discover others that cause problems then I’ll do my best to fix them.
Message Filtering
Why not use std::cout or an existing type from the Standard Library? Allow me to introduce runtime message filtering:
myStream << Filter( 10 ); myStream << DefaultPriority( 5 );
Messages with a Priority less than or equal to the Filter value are output to the final OutputTarget. Messages with a priority higher than the Filter are discarded. Lower priority value means higher message priority (0 = highest): after consideration I reasoned that large numeric values are less meaningful, especially when you aren’t sure of the underlying type (currently a uint8_t).
You specify per-message priority using the Priority stream manipulator:
myStream << Priority( 11 ) << "This text WILL NOT APPEAR in the log as the Priority value injected is higher than the current filter (10)." << endl; myStream << "This text WILL APPEAR as the priority has now been reset to the last set default (5) during the flush of the previous output" << endl;
Member functions are also directly accessible in the stream object:
myStream.SetFilter( SettingsTypenewValue ); myStream.SetDefaultPriority( SettingsType newValue ); myStream.SetPriority( SettingsType newValue );
note that SettingsType is, currently, just an alias for the aforementioned uint8_t.
A final member function and corresponding manipulator control enabling and disabling a stream’s output entirely:
mySteam.Enable( 0 ); myStream << Enable( 1 );
String Conversion
Optional string type conversion.
C++ ’11 gave us two new character types and various new string encodings but, despite these additions, when you send a non-native string to a Standard Library stream (say a wchar_t string to a char stream) with operator << it is caught by a generic pointer handler so your non-native (to the stream) string is almost always output as a numeric value rather than a string of text.
Additionally, conversion of many types into strings isn’t supported with char32_t and char16_t streams: Microsoft’s Standard Library implementation just produces an error relating to std::numpunct<_Elem>::id whilst G++ and Linux just seem to silently pretend that you never attempted to write a numeric to the stream because whilst your code will compile and run you certainly won’t find that numeric in the stream buffer.
I decided to catch all three character types foreign to a stream’s internal type and perform integral narrowing or widening rather than just display a numeric pointer value as the Standard Library currently does (when it works). This conversion is obviously not always particularly successful when narrowing large codepoints, but I felt it a better fit for the likely usage of this library. This narrowing/widening behaviour is always on but I may move this to a preprocessor define at some point – it is easy enough to achieve yourself should you wish.
Secondly, I wanted to be able to convert strings into the stream’s closest UTF representation, also via pointer catching functions. This wasn’t straightforward and of course it isn’t always terribly useful considering that the underlying character type of an interface like a terminal is often just single byte per character, so recoded strings are still very much dependent on OutputTarget support. This feature does perform well where files are the stream target though as I perform the file writing in the example OutputTarget classes via kernel OS calls.
Some assumptions had to be made with string conversion – not least because of differences between platforms (wide characters having different widths on Windows and Linux for example).
If you want to use converting streams then you need to specify that policy in your declaration. The OutputStream type aliases provided allow you to declare a UTF converting stream very easily:
StreamStdOut< char, ConvertingStream_t > myStream;
See “StreamAndChannelAliases.h” for the full template syntax for the helpers.
OutputChannels (see next section) can also use the ConvertingStream_t policy and OutputChannels with differing policies can still happily share the same target OutputStream.
Note that string conversions are only available via operator << presently – I have no intention just yet of implementing a full basic_ostream<> member function interface.
OutputChannel
An OutputChannel is an additional object required if more than one thread needs to access the OutputStream concurrently. They require you to specify an ID, which you could use to identify separate areas of program functionality. Each ID gets its own StreamSettings so they don’t interfere with channels using different IDs on the same stream(s). Channels use their own buffers so can do most of their work without any synchronisation penalty. They are only a touch more involved to setup: they require a StreamList (just an alias for a std::vector of pointers to the OutputStreams they are to write to) at construction, e.g.:
OuputChannel< char > myChannel( 0, { &myStream }, true );
Again, the above is shorthand for a constructor that is using some default parameters. The full syntax is:
OutputChannel( int channelID_, std::vector< BasicStream_t< type > * > const& streams_, bool isMultiThreadChannel_ = true, OutputStamp & stamp_ = OutputStamp::GetDummyStamp(), StreamSettings * initSettings_ = &GetDefaultChannelSettings() )
The example creates an OutputChannel with an ID of 0 – ints are used to facilitate the use of enums for channel IDs – that attaches to the myStream object (from earlier in the example text) and specifies that the channel will be used by multiple threads. The final two settings optionally specify an OutputStamp instance to use for message prefixing and custom initial StreamSettings for the channel.
If you don’t need multiple thread safety for a particular OutputStream but still want the benefits of multiple channels (independent filtering despite ‘many writing to one or more’) then set the isMultiThreadChannel_ parameter in the constructor to false as this will use an optimised buffer without the synchronisation overhead.
OuputChannels can be instanced on a thread’s stack or by using C++ 11’s thread_local. If using thread_local then prefer the second of the following examples if, like me, you want every possible piece of assembly code optimised away when required:
Option One: thread_local OutputChannel< char >( construction params... ); Option Two: TLS_OUTPUTCHANNEL< char >( construction params... );
and of course with an extern prefix if you want to declare in a header.
This is the one place I had to relent on my goal and still offer a preprocessor define to ensure removal of all code because of the way Microsoft’s compiler (and possibly others) handle thread_local storage. The tiny bit of TLS code generated by the compiler for an otherwise empty object probably won’t bother most people, but it did me.
Note that if you use the thread_local option to define your OutputChannel at global scope then you will likely see some unreleased memory warnings if you use the ‘on exit’ heap-checking functions provided by the Windows system libs. This is because some threads won’t have destroyed their copy of the OutputChannel, and the buffer it creates, before the main thread calls the heap check function – you can verify that all is actually OK by hiding the OutputChannel in a function that returns a reference to a static thread_local.
When an OutputChannel attaches to an OutputStream at construction, any OutputStamp specified in that stream’s constructor will no longer be used. You must specify an OutputStamp class instance for the channel if you want message prefixing to work with channels. Again, this is an efficiency optimisation as all message prefixing is performed in local buffers to minimise contention.
Each OutputChannel can attach to multiple OutputStreams. I have set a somewhat arbitrary maximum of 32 individual shared stream objects in the source – you can have as many non-shared streams as you wish. Maximum number of OutputChannels also has a cap, 64 at present. Tweak away if needed…
Remember that each OutputChannel ID has its own StreamSettings structure so manipulators and member function calls used will only effect that channel and not any other channel(s) attached to the same OutputStream(s) -providing you give your channels different IDs.
If you require UTF string conversion when using OutputChannels then note that the appropriate base class template must be specified for the channel instance.
Example OutputStreams
All example OutputStream types (actually OutputStream_t classes taking an OutputTarget_t template parameter) have the following shorter aliases defined:
StreamFile< T_ > StreamStdOut< T_ > StreamConsole< T_ > StreamDevStudio< T_ >
The latter two being Windows only – you can use a StreamConsole< wchar_t > for UTF16 Unicode output to your Win32 console. If your application is a Windows GUI application then a console window will be created alongside.
Streams are safe and reliable with char and wchar_t types but char16_t and char32_t support is still somewhat flaky – mainly because those types don’t cooperate with the existing Standard Library implementations I’ve tried or indeed with many system API output functions or devices.
Note that if you want StreamStdOut to go to std::wcout instead of std::cout on platforms that support it, you must have USE_STD_WCOUT defined.
OutputStamp
Aside from the default “do nothing” message prefixer seen in the constructors above, I provide two other singleton OutputStamp classes:
The first is a system date & time stamp (with milliseconds also appended):
StreamStdOut< char > myStream( nullptr, SystemTimeStamp< char >::GetInstance(), &GetDefaultChannelSettings() );
The second is intended purely as an example of an OutputStamp class with a state, one that can write a prefix of variable length (up to a maximum length which the OutputStamp class must make available to its clients):
LineStamp< char >::GetInstance()
OutputStreams: Contents Design Profiling
Design
Here’s where I try to explain the design in a little more detail. The easiest route is probably the one that starts with the OutputTarget and works back to the streams and channels that write to it.
Here’s a link to the larger version of my diagram showing the class relationships, with apologies for any UML errors and omissions:

OutputTarget & OutputBuffer
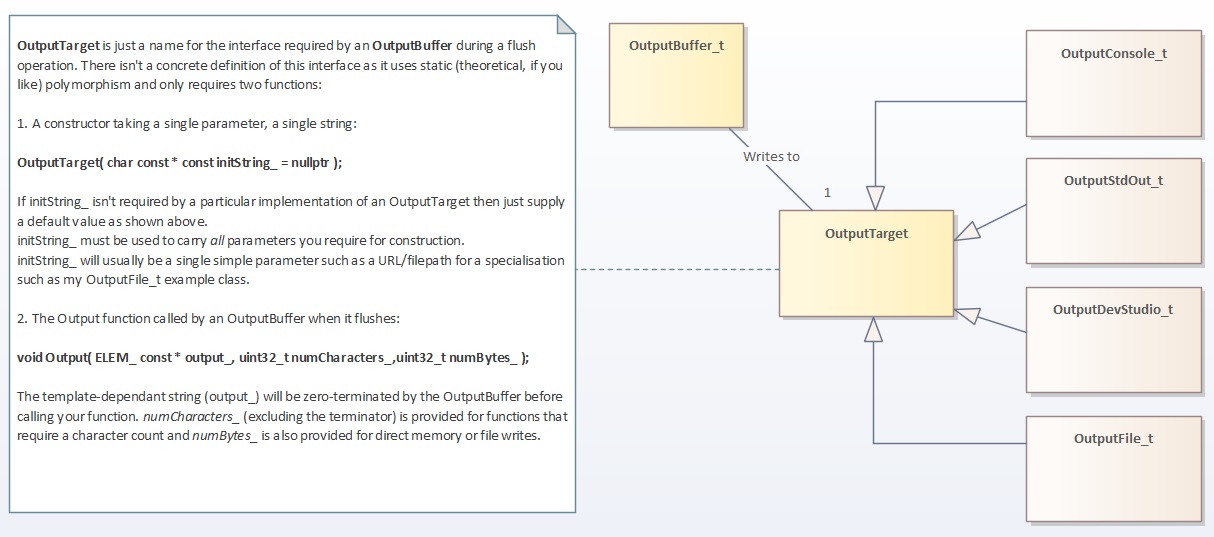
Whilst OutputTarget is shown alongside other classes in the diagrams, you will find no abstract class or interface definition within the source.
OutputTargets.h and .cpp contain my example classes that satisfy the above interface – all templates themselves so they can interface with streams and channels of various character widths. An OutputTarget is encapsulated within an OutputBuffer via a template parameter:
OutputStreams.h
...
template < typename ELEM_, template< typename > typename TARGET_ >
class OutputBuffer_t : public BasicBuffer_t< ELEM_ >
{
...
TARGET_ m_outputInterface;
}
The Output(…) function of the OutputTarget is called during the OutputBuffer’s implementation of sync()
template< typename ELEM_ >
class MyOutputTarget
{
...
void Output( ELEM_ const * output_, uint32_t numCharacters_, uint32_t numBytes_ );
...
}
class OutputBuffer_t : public BasicBuffer_t< ELEM_ >
{
...
virtual int sync() override
{
...
m_outputInterface.Output( base::pbase() + offset, numCharacters + stampLength, numBytes );
...
}
...
}
sync() performs the filtering and prefixing legwork before forwarding the string to the OutputTarget, presenting it with a string buffer pointer along with character and byte counts. The buffer is zero-terminated though the terminator is not included in either count.
OutputStream
The OutputBuffer is itself a template parameter to an OutputStream – the core template class for a stream object.
template< typename ELEM_, template< typename > typename TARGET_, template< typename > typename STREAMBASE_ >
class OutputStream_t : public STREAMBASE_< ELEM_ >
{
...
OutputStream_t( char const * const initString_ = nullptr, OutputStamp & stamp_ = OutputStamp::GetDummyStamp(), StreamSettings * initialSettings_ = &GetDefaultChannelSettings() )
...
OutputBuffer_t< TARGET_, ELEM_ > m_buffer;
...
};
OutputStream derives from BasicStream via the Stream or ConvertingStream template class. These two empty classes exist purely to permit text caught by various helper functions to be dispatched correctly.
BasicStream extends std::basic_ostream with some virtual functions for message filtering, a mutex and a flag used to indicate that the stream is in multithread mode and connected to upstream OutputChannels.
The OutputStream type is further aliased, in StreamAndChannelAliases.h, into helper templates named according to their OutputTarget destination:
template< typename T_, template< typename > typename U_ = Stream_t > using StreamFile = OutputStream_t< T_, OutputFile_t, U_ >;
These are all contained within a preprocessor block that redirects those aliases to a NullStream template class if STREAM_OUTPUT_STRIP is defined. NullStream is a dummy class exposing the minimum empty function set needed to allow the compiler to optimise stream and channel objects away in release builds along with some operator << helpers to do the same.
As per the UML and the OutputStream_t constructor, an OutputStream uses StreamSettings and an OutputStamp.
StreamSettings
The StreamSettings structure holds the current runtime filtering flags for the stream. These are: Enable, Priority, Default Priority, and Filter. All flags are atomic as this structure is also used by OutputChannels which must be thread-safe.
Enable is a simple on/off for stream output, Filter sets a priority cap – messages with priority values greater than this filter value are discarded. Default Priority sets the priority value for all messages (until changed) and Priority is a temporary used to specify Priority only until the next flush() , at which time Default Priority is restored.
OutputStreams and OutputChannels both provide member functions to change these settings and I’ve provided manipulator functors that can be injected into a stream or channel directly alongside other content much like other Standard Library stream manipulators.
OutputStamp
This is a message prefixing base class used by OutputStreams and OutputChannels to write an optional prefix to the front of the buffer before forwarding to an OutputTarget.
The base class defines the interface and provides a singleton instance which is used as a default parameter by the constructors of both OutputStream_t and OutputChannel_t.
class OutputStamp
{
public:
virtual int GetMaxLength() const { return 0; }
virtual int GetLength() const { return 0; };
virtual int WriteStamp( void * ptr_ = nullptr ) { return 0; }
virtual void Lock() {}
virtual void Unlock() {}
static OutputStamp & GetDummyStamp()
{
static OutputStamp instance;
return instance;
}
OutputStamp() = default;
virtual ~OutputStamp() = default;
};
The Lock() and Unlock() functions are called only by OutputChannels when running in multithread mode: they call GetLength() and WriteStamp() in succession and those two functions need to agree on the character length of the next prefix write.
I have provided two example prefixing classes using this base class: SystemTimeStamp and LineStamp: both of which are safe for concurrent access of their singleton instances. The LineStamp is a very simple example that variable length prefixing works. Both example classes are templatised to work with different character types and provide singleton instances by design only – OutputStamps can be different object instances on each thread should you wish, it’s all down to your design and how and where you construct them.
OutputChannel & ChannelBuffer
OutputChannel is a thread-safe class which attaches to one or more OutputStreams. Message construction including any prefixing is handled locally until such time as a flush() is triggered.
The OutputChannel class is similar to an OutputStream – it derives from BasicStream via Stream or ConvertingStream:
template< typename ELEM_, template< typename > typename STREAMBASE_ >
class OutputChannel_t : public STREAMBASE_< ELEM_ >
{
...
public:
OutputChannel_t( int channelID_, std::vector< BasicStream_t< type > * > const& streams_, bool isMultiThreadChannel_ = true, OutputStamp & stamp_ = OutputStamp::GetDummyStamp(), StreamSettings * initSettings_ = &GetDefaultChannelSettings() )
...
};
The constructor requires a channel ID, a vector of pointers to one or more OutputStream objects that the channel will write to, a multi-thread usage flag, an optional OutputStamp instance and optional non-default StreamSetting values.
An OutputChannel creates a ChannelBuffer. This buffer derives from std::basic_stringbuf and has two specialisations to write to each OutputStream the channel attaches to, with and without using mutexes. The specialisation chosen depends upon the construction parameter isMultiThreadChannel_
OutputChannels also use a group of external arrays to control channel initialisation and to hold the StreamSettings for each channel ID. This ensures that existing channel settings are not reset when a new channel object is constructed using an existing channel ID, e.g.: a new system thread starting and initialising a global-scope thread_local OutputChannel. Also present is a reference count of the number of channels attached to each stream so that the stream’s buffer is reset correctly once the last channel has detached. Most of the work with these data occurs in the OutputChannel’s constructor and destructor, though the OutputStream class destructor also clears its reference count to avoid inadvertent access by a channel following its destruction.
If you do intend to create and destroy many streams and channels that are shared by threads then it is advisable to destroy your channel objects before you destroy the streams they are attached to – this is because the shared stream array lookup table is accessed without the mutex within the OutputChannel’s sync() function. I felt this a worthwhile caveat rather than make that array’s elements atomic and incur a performance hit – it’s a fairly trivial tweak to change to atomics but not one I felt was necessary.
OutputStreams: Contents Design Profiling
OutputStreams Performance Profiling
Test Environments:
- Windows 32-bit build with Microsoft cl.exe via CMake/Ninja with standard CMake release settings.
running on: Windows 10 Home Edition. Intel(R) Core(TM) i7-1065G7 CPU @ 1.30GHz, 8Gb RAM, 512GB SSD
- Linux(a) 32-bit build with G++ version 9.4.0 via CMake/Ninja with standard release settings
running on: Ubuntu 20.0 LTS 64bit. VMWare Workstation 16 Player on Windows PC (from 1)
- Linux(b) 32-bit build with G++ version 9.4.0 via CMake/Ninja with standard release settings
running on: Ubuntu 20.0 LTS 64bit Workstation. Intel(R) Core(TM) i5-3230M CPU @ 2.60GHz, 8Gb RAM, 1TB HDD
- Linux(c) ARM build with G++ 8.3.0 via CMake/Ninja with standard CMake release settings
running on: Raspberry Pi 4
Method:
Started multiple threads using C++ ’11 <thread> library and timed using std::chrono::high_resolution_clock. Ran each set of output command tests fifty times via a main thread loop, storing results of each.
Worker threads for each command loop test:
Timing commenced when the last thread had initialised stack locals. Each thread ran same code, sending identical text requirements to the output method, incremented the total count and looped until the total count reached the iteration count – at this point they exited. The main thread read the end time following the last join() and started the next test. Which thread did the most work wasn’t important – I was just looking to collect raw throughput figures.
Common Test Parameters:
| Number of Threads running each sample loop concurrently: | 3 |
| Total number of output commands per sample: | 50,000 |
| Samples gathered per Output Method per Test: | 50 |
Test 1:
| Output Method and data sent: | PRINTF: printf( “P: Thread %d writing to std::cout. Count = %d\n”, threadNumber_, count ); OUTPUT_CHANNEL (to StreamStdOut<char> ) channelOne << “C: Thread ” << threadNumber_ << ” writing to std::cout. Count = ” << count << std::endl; STD_COUT std::cout << “S: Thread ” << threadNumber_ << ” writing to std::cout. Count = ” << count << std::endl; |
Test 1 Results:
- Windows x86
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | 938 ms | 954 ms | 6,013 ms |
| Worst | 969 ms | 1,093 ms | 6,439 ms |
| Average: | 948 ms | 973 ms | 6,244 ms |
- Linux(a) – x86 Virtual
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | 328 ms | 309 ms | 239 ms |
| Worst | 590 ms | 932 ms | 639 ms |
| Average: | 460 ms | 557 ms | 502 ms |
- Linux(b) – x86 Dedicated
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | 348 ms | 352 ms | 356 ms |
| Worst | 397 ms | 471 ms | 424 ms |
| Average: | 359 ms | 419 ms | 388 ms |
- Linux(c) – ARM
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | 1,282 ms | 1,179 ms | 1,350 ms |
| Worst | 1,680 ms | 1,377 ms | 1,754 ms |
| Average: | 1,525 ms | 1,273 ms | 1,570 ms |
Test 2:
| Output Method and data sent: | PRINTF printf( “P: String Literal 1: %s Floating point 1: %f, Two integers %d %d, One hex integer %x. Second String Literal %s, a double %f\n”, StringLit1, Float1, Int1, Int2, Int3, StringLit2, Double1 ); OUTPUT_CHANNEL (to StreamStdOut<char> ) channelOne << “C: String Literal 1: ” << StringLit1 << ” Floating point 1: ” << Float1 << ” Two integers ” << Int1 << ” ” << Int2 << “One hex integer ” << std::hex << Int3 << ” Second String Literal ” << StringLit2 << “, a double ” << Double1 << endl; STD_COUT std::cout << “S: String Literal 1: ” << StringLit1 << ” Floating point 1: ” << Float1 << ” Two integers ” << Int1 << ” ” << Int2 << “One hex integer ” << std::hex << Int3 << ” Second String Literal ” << StringLit2 << “, a double ” << Double1 << std::endl; |
Test 2 Results:
- Windows x86
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | a) 1,638 ms b) 1,639 ms | a) 1,504 ms b) 1,505 ms | a) 26,762 ms b) 26,979 ms |
| Worst | a) 2,235 ms b) 2,172 ms | a) 2,441 ms b) 2,235 ms | a) 34,186 ms b) 32,920 ms |
| Average: | a) 1,827 ms b) 1,959 ms | a) 1,712 ms b) 2,048 ms | a) 29,173 ms b) 31,158 ms |
- Linux(a) – x86 Virtual
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | a) 1,145 ms b) 1,197 ms | a) 810 ms b) 848 ms | a) 1,216 ms b) 1,288 ms |
| Worst | a) 1,662 ms b) 1,587 ms | a) 1,438 ms b) 1391 ms | a) 1,860 ms b) 1,884 ms |
| Average: | a) 1,387ms b) 1,432 ms | a) 1,130 ms b) 1,085 ms | a) 1,521 ms b) 1,557 ms |
- Linux(b) – x86 Dedicated
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | a) 1,038 ms b) 992 ms | a) 1,011 ms b) 1,255 ms | a) 990 ms b) 985 ms |
| Worst | a)1,155 ms b) 1,168 ms | a) 1,249 ms b) 1,112 ms | a) 1,108 ms b) 1,121 ms |
| Average: | a) 1,097 ms b) 1,089 ms | a) 1,121 ms b) 1,112 ms | a) 1,042 ms b) 1,047 ms |
- Linux(c) – ARM
| Method: | PRINTF | OUTPUT_CHANNEL | STD_COUT |
| Best | a) 3,349 ms b) 3,257 ms | a) 2,752 ms b) 2,822 ms | a) 3,214 ms b) 3,303 ms |
| Worst | a) 3,988 ms b) 4,057 ms | a) 3,137 ms b) 3,219 ms | a) 4,037 ms b) 4,006 ms |
| Average: | a) 3,624 ms b) 3,551 ms | a) 2,903 ms b) 2,979 ms | a) 3,702 ms b) 3,632 ms |
Observations:
- Output to std::cout seems to be handled a lot more efficiently on Linux than Windows. Linux only very occasionally showed interleaving artifacts in output on the three targets I tried, suggesting that its internal synchronisition is more efficient. Perhaps it is using internal, per-thread buffers for streams much like my own system. At some point I will investigate the headers and disassembly output of both systems a little more closely. The timings suggest that Windows std::cout is hampered by locking for each input segment sent to the stream (e.g. every operator << call), this is backed up by the interleaving noted in my blog. This does also mean, however, that if a thread crashes or is suspended during one of those calls at least you will still get all of the output to that point. I suspect Linux, like my own code, would risk losing whatever was already in the output buffer should a thread die. We also have to consider that internally, Windows timings also might be affected by converting the final char * string to a wchar_t sequence internally before sending to the console.
- Streams catch and outperform variadic printf calls when we have more complex data to output. This is unsurprising given each formatting string sent to a variadic function must be parsed for content type and each item in the variadic list must have its string size computed before the length of the final output string is known. That single function call could contain many internal library function calls and small buffer allocations – efficiency will come down to exact library implementation and how the parsing of the formatting string and the buffering of items in the variadic list is actually handled. One for the library writers to comment on… As for my OutputStreams: they are helped by the efficiency of using a single write() both from the local thread buffer to the shared stream’s buffer and from the shared stream’s buffer through to std::cout. Buffer content and size is known and fixed at the point those transactions happen, so the mutex is locked and held for the minimum possible time.
- OutputStreams perform especially well on a lightweight OS such as the default Raspberry Pi OS running on the Broadcom ARM quad-core.
Conclusion:
OutputChannels appear to compare very favourably to raw printfs in a multi-threaded environment. They are also almost as fast as native Standard Library streams when writing to system consoles but without falling victim to interleaving. This comparison looks to become even more favorable the higher the number of hardware threads due to further work being handled by local thread objects so less contention on the target. This appears to be backed up by the performance on the 4 core Linux machine (even a virtual one) and the ARM when compared to the 2 core dedicated Linux machine.
For future investigation:
- Further research on all of the above
- Profiling on writes to files using similar tests
OutputStreams: Contents Design Profiling